The Past and Future of Clinical Trials – Part II
An effective trial needs to be patient-centric, with solid study design and execution, supported by real-time analytics. It should also have good patient input and provide insights to the sponsor.
Designing, conducting, executing, and reporting on clinical trials involves many complex issues. These issues include, but are not limited to, the duration of the trial, the burden the trial places on its participants, communication between healthcare providers and patients, scheduling, tracking, and reporting. These issues directly impact how a trial is planned, executed, and tracked. As data are collected, it then becomes important to generate analytics and share insight with sponsors. It is also important to collect feedback from patients to make future trials better.
One of the keys in designing an effective trial is putting the patient at the heart of the overall plan. Although it seems commonsense, Patient Centricity is a comparatively new development. Not only does it enhance the patient experience, one study reported that patient-centric trials took almost half the time to recruit participants, recruited double the number of patients, and the study drug was 19% more likely to be launched. Improved patient centricity means more efficiency in conducting a trial and reduction of the overall patient burden.
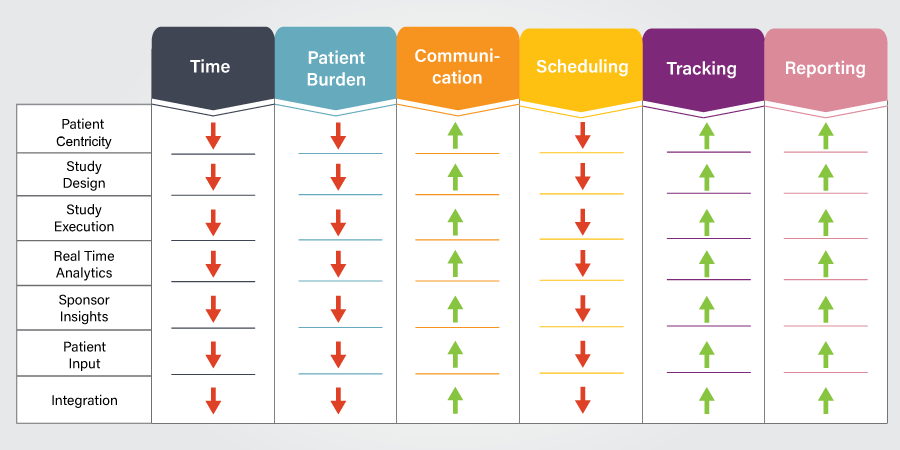
So, when designing a clinical trial, what should we aim for? The Figure above illustrates that. We should have a design that reduces the time needed to plan and execute it and espouses better communication across the board between the different parties—patients, sponsors, and administrators, including the principal investigator and support staff. It should also help in reducing complexity in scheduling, tracking, and reporting. Artificial intelligence (AI) can help improve performance in each of these areas.
AI is receiving considerable attention in a wide range of current applications. AI is the generic study of how machines can be made to produce behaviors that are associated with intelligence as found in nature. Machine learning, which is a sub-field of AI, focuses on generating systems that can improve their own performance over time, as well as the theoretical foundations and applications of computational aspects of these systems. Some examples of machine learning include reinforcement learning, neural networks, and evolutionary and swarm intelligence algorithms.
Commonly, machine learning algorithms are used to estimate a relationship between a system’s inputs and outputs using a learning data set that is representative of the behavior found in the system. This learning can be either supervised (with labeled examples) or unsupervised (without labeled examples), and it can be static or dynamic.
More specifically, machine learning is the process by which a computer can learn to do something—that something might be as simple as recognizing handwritten checks, or as complex as safely driving a car on its own. At the core of this technology are mathematical models based on foundations of statistical analysis, statistical model building, and probability. Recently, hardware designs have caught up with the intellectual concepts, making it feasible to implement large-scale AI systems. Large neural networks (deep learning, convolutional, recurrent, long/short-term memory) and other equally innovative and computational intensive model structures can be used to estimate complicated multi-dimensional data. For example, with regard to improving clinical trials, it is now possible to ingest data from hundreds of similar trials and generalize as to why some were successful and others were not. Other components of machine learning, such as evolutionary algorithms, swarm intelligence, and reinforcement learning can be applied generally across multiple data structures, including neural networks but also fuzzy systems, random forest classifiers, and others, to yield rapid insights that were not available 5-10 years ago.
AI also involves natural language processing (NLP), a technology that allows a computer to convey an understanding of text and process that text for human consumption. For example, when details of a new trial are submitted to ClinicalTrials.gov—a repository of most clinical trials in the US—some of those details are in structured format, but others are not, such as eligibility criteria. If an eligibility criterion indicates that a pediatric study should include patients between 13 to 18 years of age, there are numerous ways of stating that information. Similarly, adult onset diabetes may be listed as Type 2 diabetes, Type II diabetes, diabetes mellitus 2, T2DM, or other options—each of which describes the same set of disease. Computers have to be programmed to handle the inherent variability of language to accurately model the variables and parameters of interest and NLP tools offer a solution to this complex problem.
Just as NLP is a way to model and understand human language, and ML offers tools to help learn models of complex data, predictive analytics combines these technologies so that we can predict how likely a particular event is to happen based on past data. For example, by looking at certain personal data, we may be able to predict if a trial participant will more or less likely to continue with the trial or drop out—a vital piece of information that can make the difference between success and failure. We can also estimate and quantify the burden that a patient is experiencing in a trial and then use predictive analytics to address the “what if” scenarios that could be expected to lower that burden. In turn, predictive analytics can also be applied from the sponsor’s perspective to assist with study site selection, trial management, funding allocation, and other matters.
How can these emerging technologies have a positive impact on clinical trials? We will address some specifics and some practical examples in the next post.